Week 9 & 10: Introduction to Bioinformatics
Bioinformatics
Cell is the basic structural, functional and biological unit of all known living organisms.
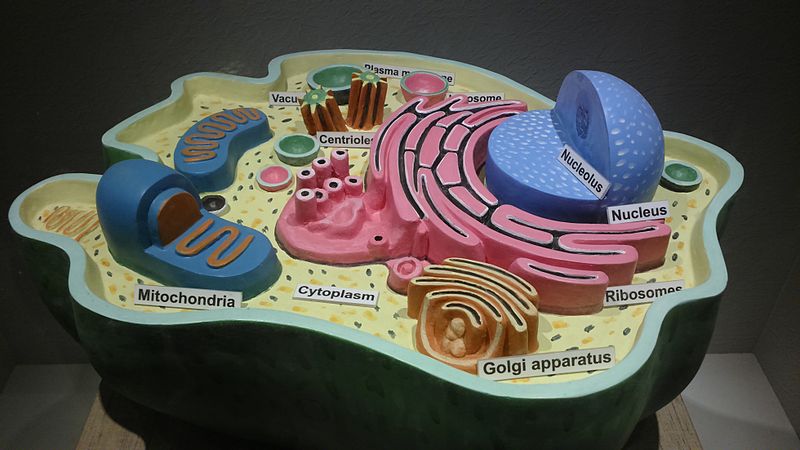
Cell nuclei contains cell’s genetic materials DNA and RNA that forms the chromosomes. Human has 23 pairs of chromosomes. Genome is distributed along these chromosomes.


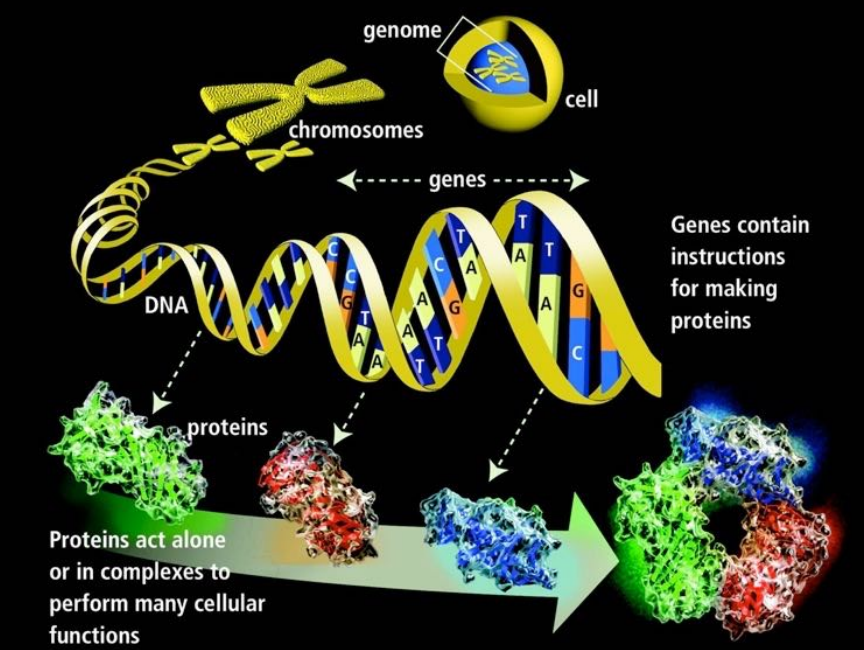
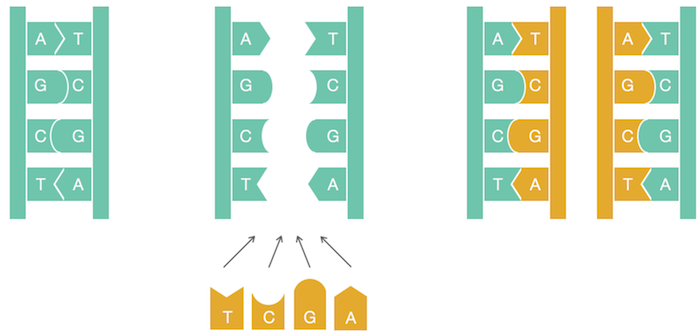
DNA stands for Deoxyribonucleic acids. DNA has two strands of four types of nucleotides.
- Adenine (A)
- Guanine (G)
- Cytosine (C)
- Thymine (T)
The two polymers are complementary to each other.
![]()
Genome Data
This is how gnome data looks like

Genome replication
Genome replication basically is to copy or make a clone of the gnome. Like copying that text but it is not for one time it is for million of times. Gnome replication is a complex process and till now it is not fully understood by the biologists.
Dna Replication
Finding replication origin is a key for many applications gene therapy, genetic modified food like frost-resistant tomatoes and pesticide-resistant corn
The idea of gene therapy simply is to infect patient who lack a specific gene with artificial gene that encode a therapeutic protein. Once become inside the cell it will be replicated and treat the patient.
First human gene therapy experiment link
So where is engineering here. It is purely biological problem. Only biologist can find experimentally the origin of replication. Simply he could cut cell DNA to pieces and find which piece will make the cell stop replication and hence it must be the origin of replication.
It is not well defined computational problem
Hidden message in Replication origin
The Gold-Bug short story tells us about a hidden message of pirate treasures. This message must be encoded to be understood.

It was noticed that ;48 sequence is frequently repeated in that message, given that it is encoded from english and the most frequent word in english is THE we can replace ; with T, 4 with H, and 8 with E.

We have a better chance now to encode the message

So frequent word is the hidden message for decoding.
Counting words
So the first problem we need to solve is to count number of repetitions of a pattern in the text.
PatternCount(Text, Pattern)
count ← 0
for i ← 0 to |Text| − |Pattern|
if Text(i, |Pattern|) = Pattern
count ← count + 1
return count
PatternCount("GCGCG", "GCG")
> Output
2
Lets try to implement it
Getting Started with Python
Python is interpreted high level programming language for general purpose computing.
You already installed anaconda. We can use spyder IDE to run our code, but we will use jupyter notebook.

Variables
Python is untyped language
x = 5
y = 'Hello SBME'
Lists
# Initialize the list
myList = [2, 55, 565]
# add an element at the end of the list
myList.append(8)
# Add element in specific index
myList.insert(1, 7)
print( myList ) # ??
print( myList[0] ) # ??
print( myList[3] ) # ??
print( myList[4] ) # ??
Arithmetic Operations
x = 19
y = 18
z = x / y
z = x * y
z = x + y
z = x - y
Comparison Operators
| operator | meaning |
|---|---|
| == | Equal to |
| != | Not equal to |
| < | Less than |
| > | Greater than |
| <= | Less than or equal to |
| >= | Greater than or equal to |
Logical Operations
x = True
y = False
x or y
x and y
not x
If, elif, else
x = 25
y = 20
if x < y:
print("y is greater than x")
elif x == y:
print("x and y are equal")
else:
print("x is greater than y")
Loops
for i in range(10):
print( i )
i = 0
while i < 10 :
print( i )
i += 1
Functions
def mean( list ):
sum = 0
for element in list:
sum += element
return sum / len( list )
m = mean([1,12,42,1,23,12])
print( m )
Importing Libraries
import numpy as np
Frequent words
Given a text find frequent words with a specific length k.
FrequentWords(Text, k)
FrequentPatterns ← an empty set
for i ← 0 to |Text| − k
Pattern ← the k-mer Text(i, k)
Count(i) ← PatternCount(Text, Pattern)
maxCount ← maximum value in array Count
for i ← 0 to |Text| − k
if Count(i) = maxCount
add Text(i, k) to FrequentPatterns
remove duplicates from FrequentPatterns
return FrequentPatterns
FrequentWords("ACGTTGCATGTCGCATGATGCATGAGAGCT", 4)
> Output
CATG GCAT
Reverse complement
 Given a text of DNA string get its reverse complement
Given a text of DNA string get its reverse complement
def reverseComplement(Text):
complementDict = {}
complementDict["A"] = "T"
complementDict["C"] = "G"
complementDict["G"] = "C"
complementDict["T"] = "A"
reverseComplement = "" # an empty string
for i in reversed(Text):
reverseComplement = reverseComplement + complementDict[i]
return reverseComplement
reverseComplement("AAAACCCGGT")
> Output
ACCGGGTTTT
Section Demo
You can download section demo from here
Useful links
Finding Hidden Messages in DNA (Bioinformatics I)
Exercises
Choose the correct answer
- in DNA, Adenine (A) is the complement of
- Guanine (G)
- Cytosine (C)
- Thymine (T)
- None of the above
- in DNA, Cytosine (C) is the complement of
- Adenine (A)
- Guanine (G)
- Thymine (T)
- None of the above
- DNA replication produces …… of original DNA
- different copies
- identical copies
- complemented copies
- None of the above
- Gene-Therapy is to inject the patient with an artificial gene that encodes
- Harmful protein
- Therapeutic protein
- Effectiveness protein
- None of the above
- Finding frequent words is the key algorithm to locate ….. of the DNA
- Replication origin
- Complement
- Sequence
- None of the above
- Bioinformatics replaces the lab experiments with
- Real experiments
- Computational analysis
- Advanced experiments
- None of the above
- The frequent 3-mer (3 letters word) in this DNA sequence (ATTGCATGC) is
- ATT
- ATG
- TGC
- None of the above
- The reverse complement of the DNA sequence (AAAACCCGGT) is
- CCCCAAATTG
- ACCGGGTTTT
- TTTTGGGCCA
- None of the above
- The output of the following code snippet
total = 0
for i in range( 5 ):
total += i
print(total)
- 10
- 20
- 30
- None of the above
- The output of this case is
total = 0 for i in range( 5 ): total += i print(total)
- The output of this case is
- Same as the previous question
- Different
- No output
If it is different, What is the output?