Week 7: Feature Extraction, Description and, matching
Features and feature descriptors
Features or key-points of an image are corners which are unique in the image. Harris and FAST are two different corner detectors, we have discussed Previously. Corner detectors are invariant for translation, illumination and rotation. But it is variant for scaling.
Lets see an example
Next figure shows two different scales of same image. In smaller image, it’s easy to detect that there is a corner, but what about same image in the large scale. It will be difficult to detect that corner so this feature point will not be recognized for all scales.
So size of the window will effect the detection of corners. Large corners needs large windows and smaller corners needs smaller windows.
Scale invariant feature descriptor (SIFT)
Scale invariant feature descriptor (SIFT) is not a new way to find key-points or corners that is invariant to scale. But it is a descriptor of detected corners of different image scales or image pyramids.
Image pyramids and scale-spaces
Image pyramids or image scale space is the proposed method to handle images in different scales. We have different scale-spaces
-
Gaussian scale space (Gaussian pyramid)
-
Laplacian of gaussian (LOG) scale space
-
Difference of gaussian (DOG) scale space
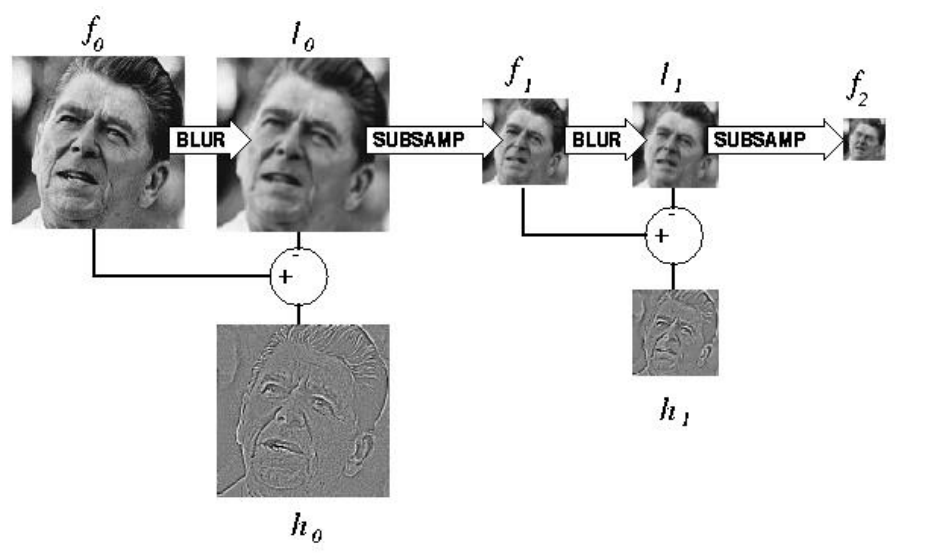
The basic idea to build scale space is shown in the following figure
Gaussian Pyramid

LOG Pyramid
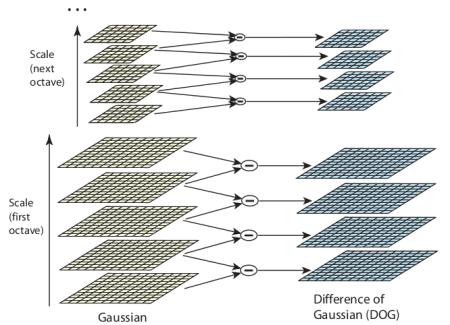
In SIFT we usually prefer DOG scale space which is an approximate of LOG and simpler in calculation.
SIFT scale space
In SIFT Pyramid we have
-
Octaves
different levels of image resolutions (pyramids levels)
-
Scales
different scales of window in each octave level (different \(\sigma\) of gaussian window)
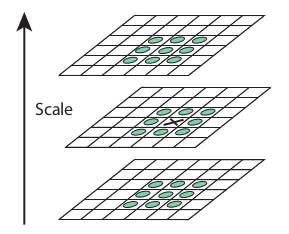
Key-point (corner) scale localization
For each key-point (corner) we need to find its best scale which have maximum value (cornerness measure). It is achieved by comparing same corner with its neighbors of above and lower scales and select scale with maximum value. For same iamge, it is not necessary for its corners to be localized at same scale.
Extract SIFT feature descriptor
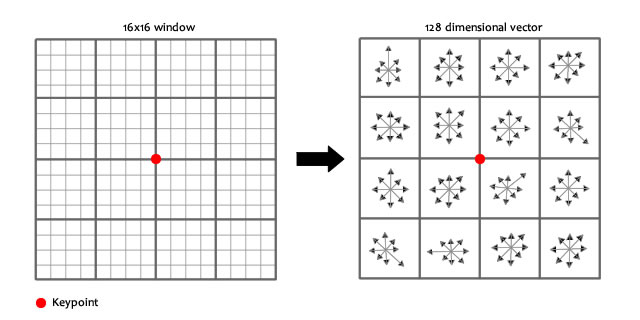
After localization of a key-point in our scale space. We can get its SIFT descriptor as follow
- Extract a \(16 \times 16\) window centered by this point.
- Get gradient magnitude and multiply it by a \(16 \times 16\) gaussian window of \(\sigma =1.5\)
- Get gradient angle direction.
- Adjusting orientation (To be rotation invariant):
- Get the gradient angle of the window and Quantize them to 36 values (0, 10, 20, …, 360)
- Locate dominant corner direction which is most probable angle (angle with max value in 36 bit angle histogram)
- subtract dominant direction from gradient angle.
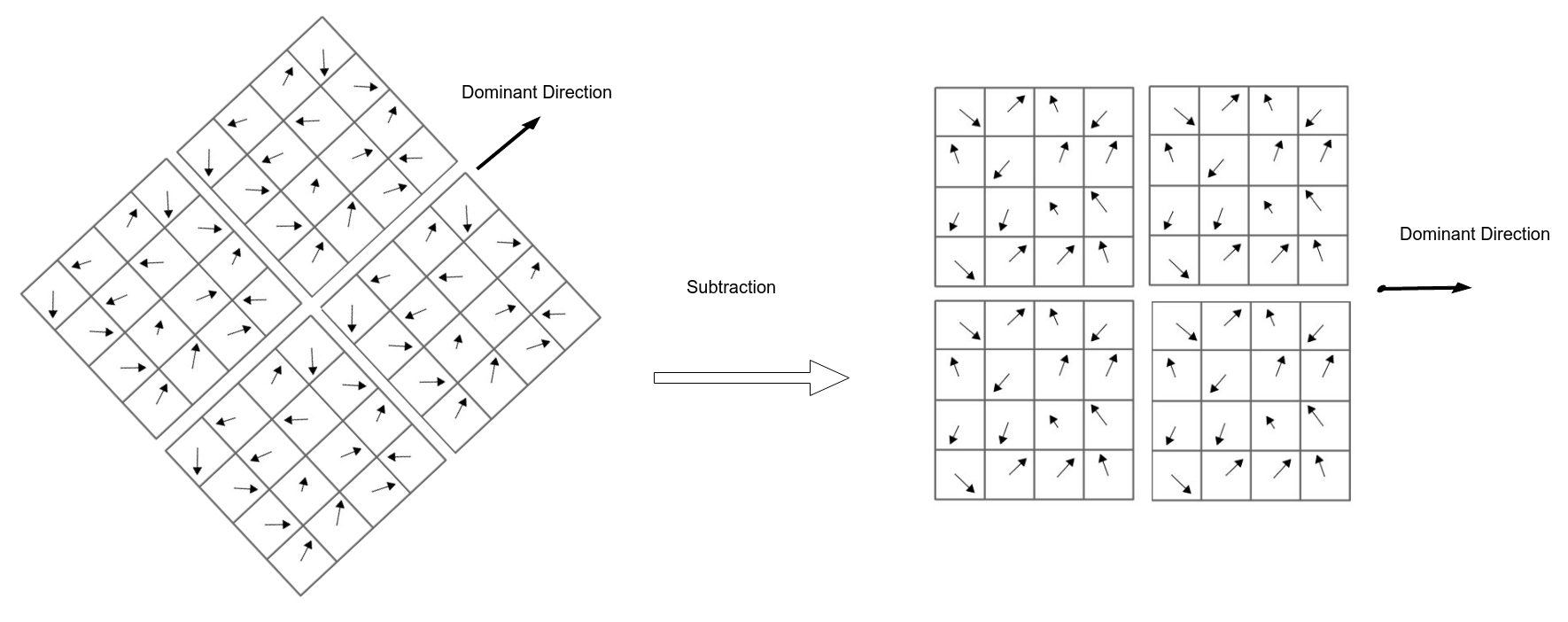
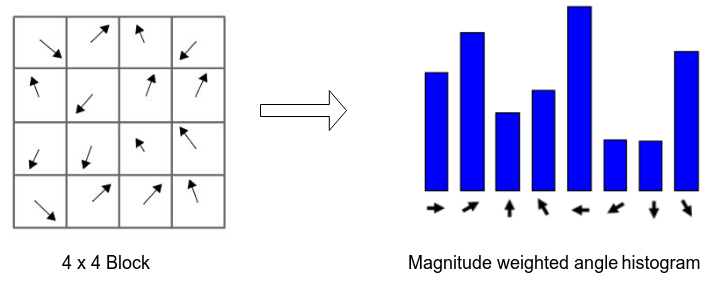
- Divide this \(16 \times 16\) patch to sixteen \(4 \times 4\) blocks
- For each block get magnitude weighted angle histogram and normalize it (divide by total gradient magnitudes).
angles (quantized to 8 angles [0, 45, 90, … , 360]) based on its relevant gradient magnitude i.e (histogram of angle 0 = sum(all magnitudes with angle 0))
- SIFT feature descriptor will be a vector of 128 element (16 blocks \(\times\) 8 values from each block)
Feature matching
The basic idea of feature matching is to calculate the sum square difference between two different feature descriptors (SSD). So feature will be matched with another with minimum SSD value.
\[SSD = \sum (v_1 - v_2)^2\]where \(v_1\) and \(v_2\) are two feature descriptors.

Brute-Force matcher
In brute-force matcher we have to match descriptor of all features in an image to descriptors of all features in another image. It is extremely expensive as we know any brute-force algorithm will guarantee getting a solution, but doesn’t guarantee getting optimal solution.
RANSAC
Random sample consensus is an iterative method for estimation of parameters of a mathematical model. We will model the transformation of points in source image to destination one, and try to find an estimate of model parameters. The basic idea of RANSAC algorithm is shown in the following flow chart.
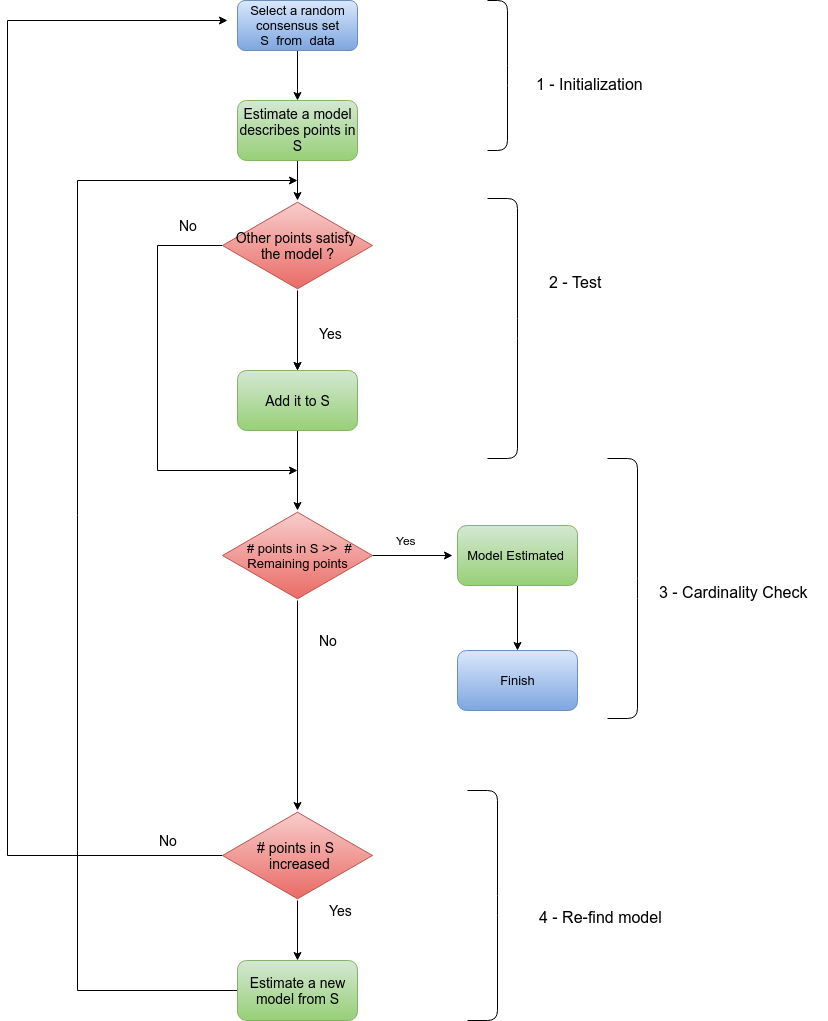
RANSAC is a robust feature matcher. For example we can model the difference between two images to a set of transformations and run RANSAC to find best model that maximize correct matching.