Week 8 - Part1: Binary Search Trees, Sets (ADT) and Maps (ADT)
- Objectives
- Trees
- Binary Search Trees (BST)
- Asbtract Data Types Built Upon BST
Objectives
- Learn about graph structures in a glimpse
- Specializing a graph into trees
- Specializing trees into binary trees
- Specializing trees into binary search trees (BST)
- Implementing set (ADT) using BST
Trees
In previous weeks, we have learned about:
- Arrays
- Linked Lists
- Queues
- Stacks
These structures are conceptually linear structures. However, there also exist very important kind of structures that are inherently non-linear (e.g trees and graphs). Trees are special case of graphs, where nodes and edges (links) do not form a cycle.
Tree Glossary
- Root: is the top node in the tree.
- Child: any node that is emerged from an upper node.
- Parent/Internal Node: node with at least one child.
- Siblings: nodes sharing the same parent.
- Leaf: node with no children.
- Edge: the link between two nodes (i.e a parent and its child).
- Path: the sequence of links and nodes to reach from one node to a descedant.
- Height of node: the number of links between a node and the furthest leaf.
- Depth of node: the number of links between a node and the root.

Synonyms
- Node = Vertex = Point
- Edge = Link = Arc
Violating Tree Structure
wikipedia
The following structures are not trees:
| Graphs that are not trees | Why? |
|---|---|
 |
cycle B→C→E→D→B. B has more than one parent (inbound edge). |
 |
undirected cycle 1-2-4-3. 4 has more than one parent (inbound edge). |
 |
two non-connected parts, A→B and C→D→E. There is more than one root. |
Binary Search Trees (BST)
Binary trees is a special case of trees where each node can have at most 2 children. Also, these children are named: left child or right child. A very useful specialization of binary trees is binary search tree (BST) where nodes are conventionally ordered in a certain manner. By convention, the \(\text{left children} < \text{parent} < \text{right children}\), and this rule propagates recursively across the tree.
 |
|---|
| A binary search tree (BST) |
 |
|---|
| Specialization from graph->tree->BT->BST |
Motivation
Efficient search & insertion/deletion in logarithmic time $O(\log(n))$
- Arrays:
- (+) efficient search on sorted arrays $O(\log(n))$,
- (-) ineffiecient insertion/deletion $O(n)$.
- Linked lists:
- (-) inefficient search $O(n)$,
- (+) efficient insertion/deletion $O(1)$.
Intuition
- Tree combines the advantages of arrays and linked lists.
- The nature of BST (i.e being ordered) makes it potential for extensive applications. For example, implementing set (ADT).
Design and Implementation: Using Linked Structures
Tree structure allows us to use recursive routines to implement the basic operations. Think of each node in a tree as a separate standalone tree. Trees can be embedded in arrays or implemented as a linked nodes (i.e using pointers). In this tutorial, we will implement the BST using linked nodes. Any node in the tree (including the root) will be represented by the type BSTNode that has the following C++ `struct:
struct BSTNode
{
int data;
BSTNode *left;
BSTNode *right;
};
Operations
Is Empty
bool isEmpty( BSTNode *tree )
{
return tree == nullptr;
}
Is Leaf
bool isLeaf( BSTNode *tree )
{
return tree->left == nullptr && tree->right == nullptr;
}
Size
int size( BSTNode *tree )
{
if ( !isEmpty( tree ))
return 1 + size( tree->left ) + size( tree->right );
else return 0;
}
Insertion
 |
|---|
| Insertion in BST, realize recursion. Author |
void insert( BSTNode *&tree, int data )
{
if ( isEmpty( tree ))
tree = new BSTNode{ data , nullptr , nullptr };
else
{
if ( data < tree->data )
insert( tree->left, data );
else insert( tree->right, data );
}
}
Search
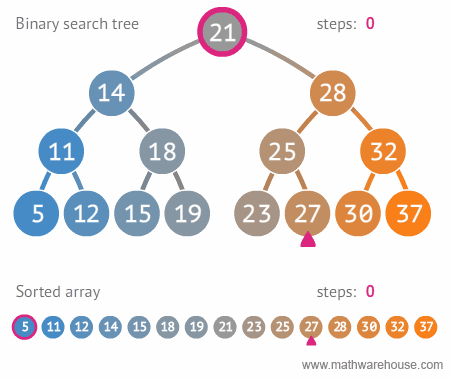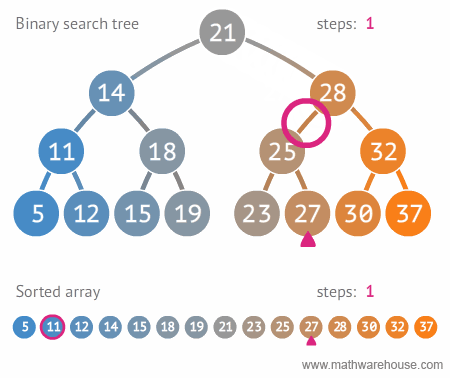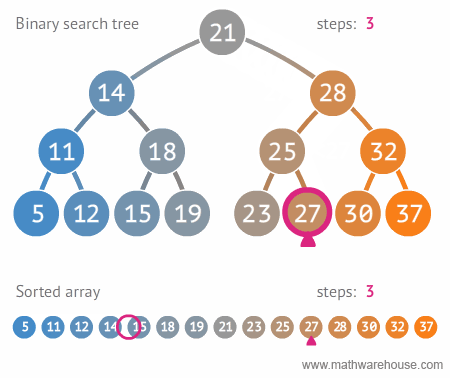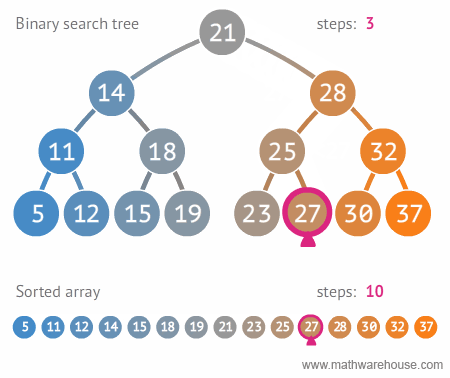 |
|---|
| Search in BST, realize recursion. Author |
bool find( BSTNode *tree, int data )
{
if ( isEmpty( tree ))
return false;
else
{
if ( data == tree->data )
return true;
else if ( data < tree->data )
return find( tree->left , data );
else return find( tree->right , data );
}
}
BST Traversal
| Pre- In- Post-order Traversals |
|---|
| Made using: Khan Academy Computer Science |
Traversal: In-order
 |
|---|
| In-order Traversal in BST, realize recursion. Source |
void inorder( BSTNode *tree )
{
if( tree )
{
inorder( tree->left );
std::cout << "[" << tree->data << "]";
inorder( tree->right );
}
}
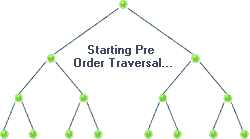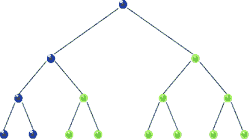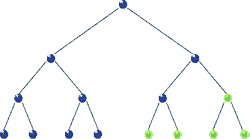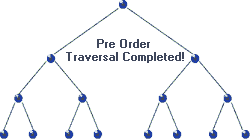
Traversal: Pre-order
 |
|---|
| Pre-order Traversal in BST, realize recursion. Source |
void preorder( BSTNode *tree )
{
if( tree )
{
std::cout << "[" << tree->data << "]";
preorder( tree->left );
preorder( tree->right );
}
}
Traversal: Post-order
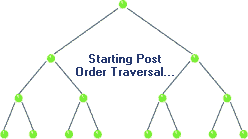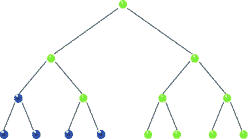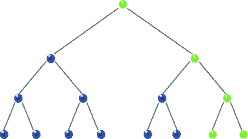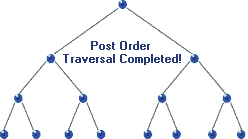 |
|---|
| Post-order Traversal in BST, realize recursion. Source |
void postorder( BSTNode *tree )
{
if( tree )
{
postorder( tree->left );
postorder( tree->right );
std::cout << "[" << tree->data << "]";
}
}
Traversal: Breadth-first
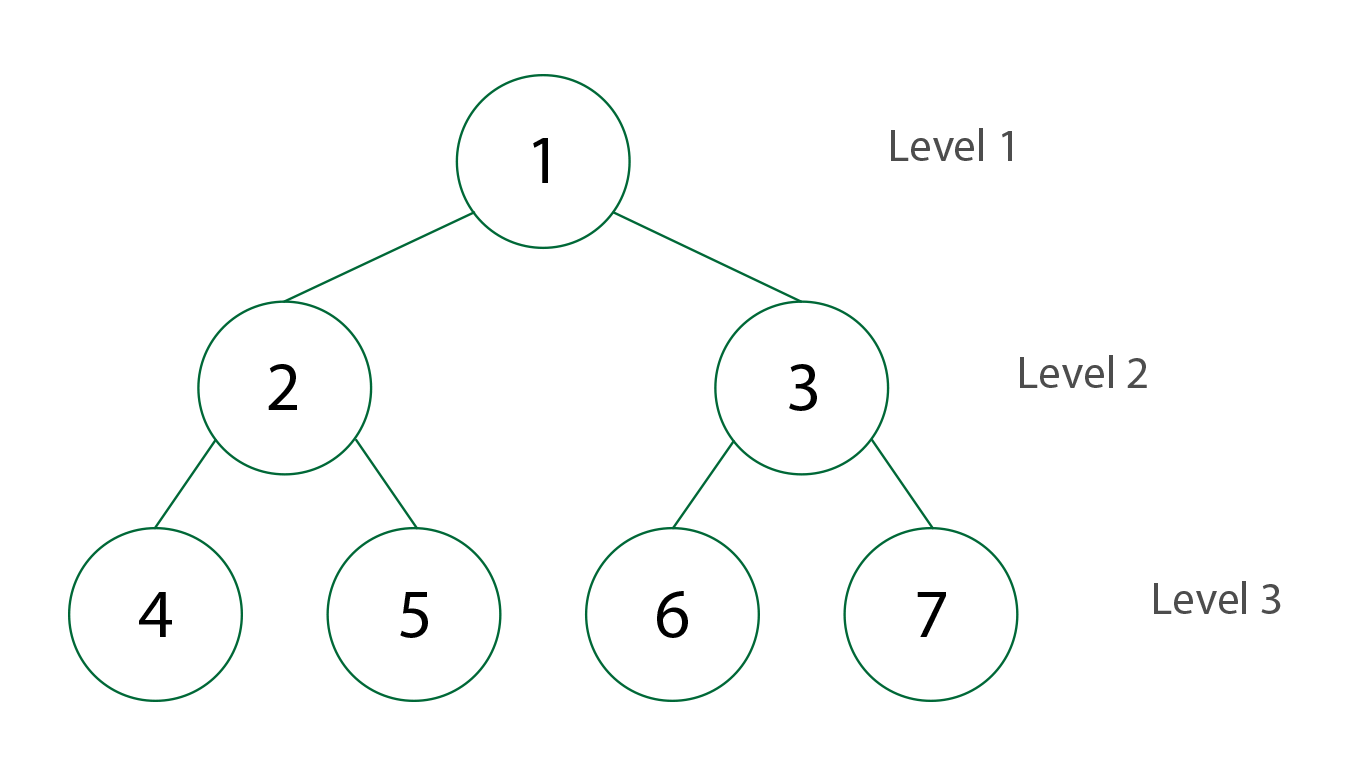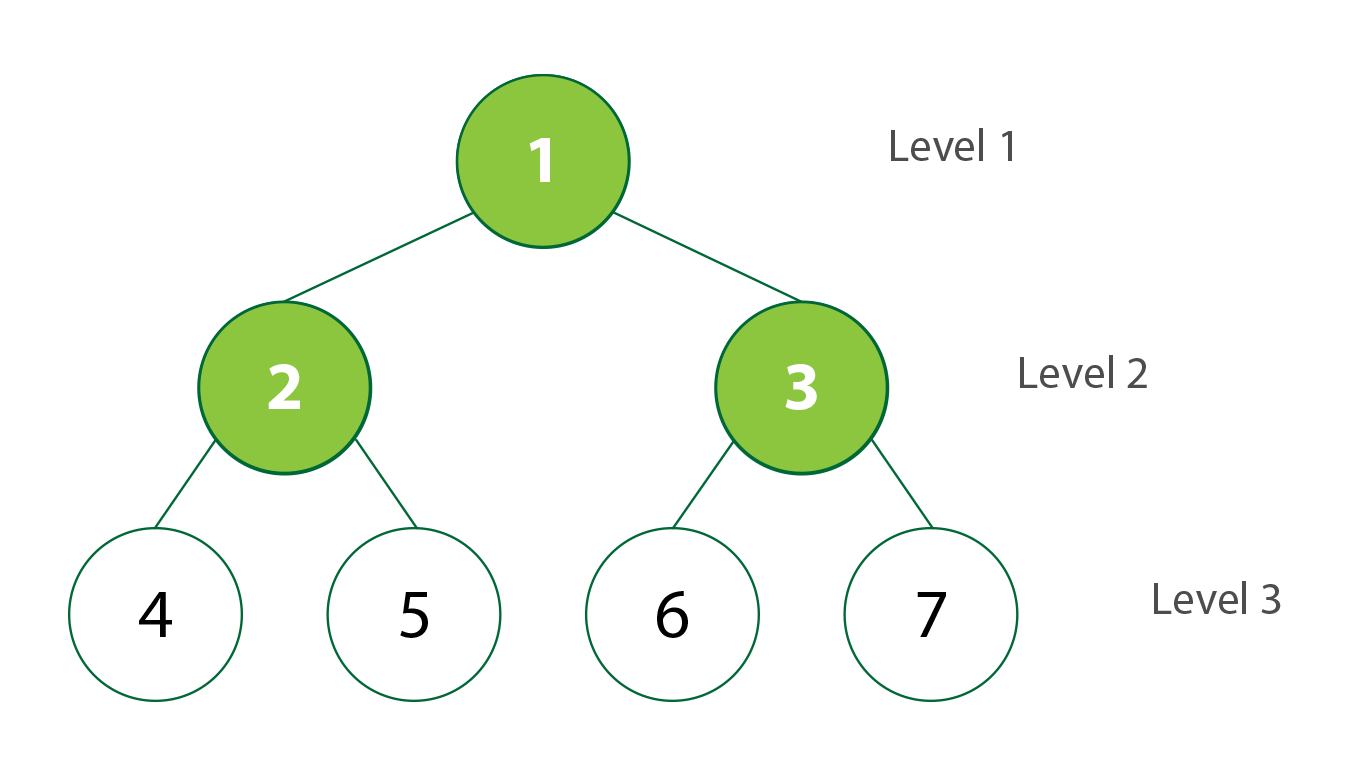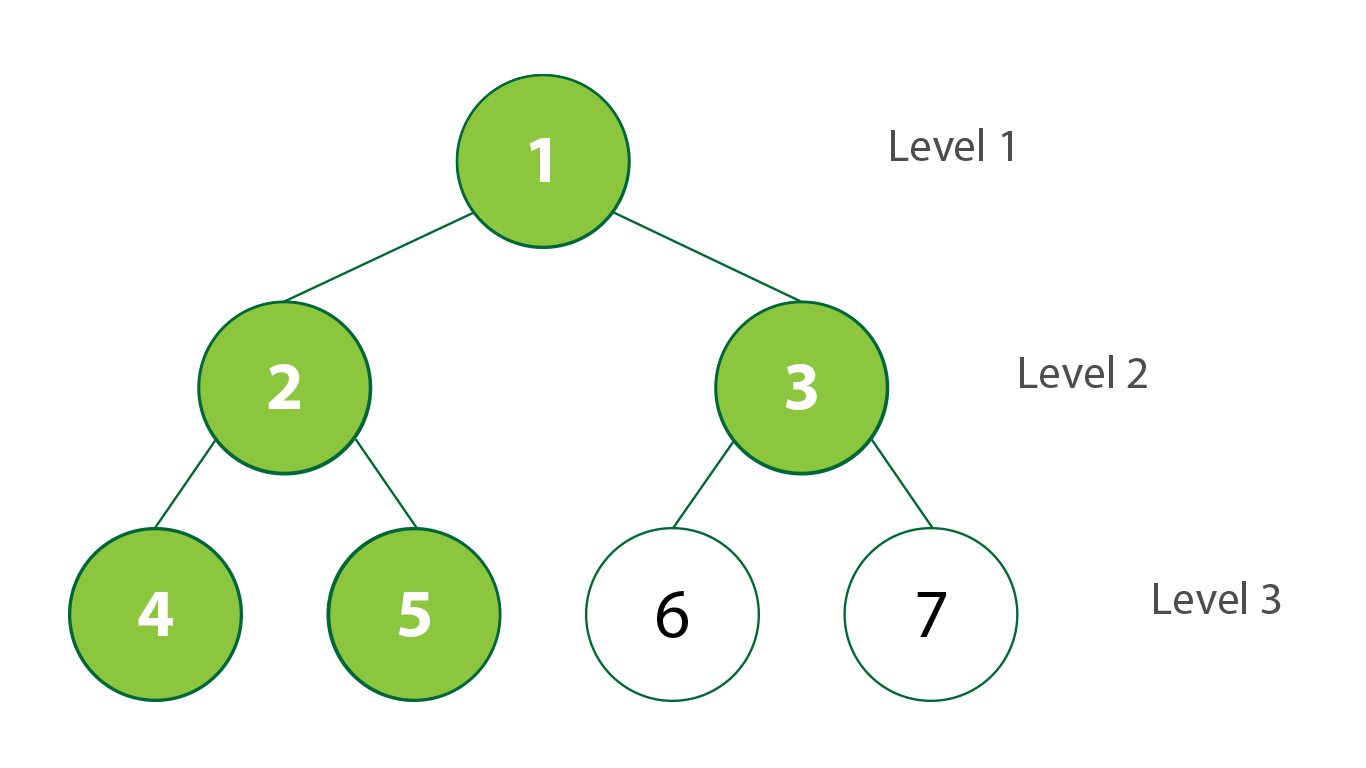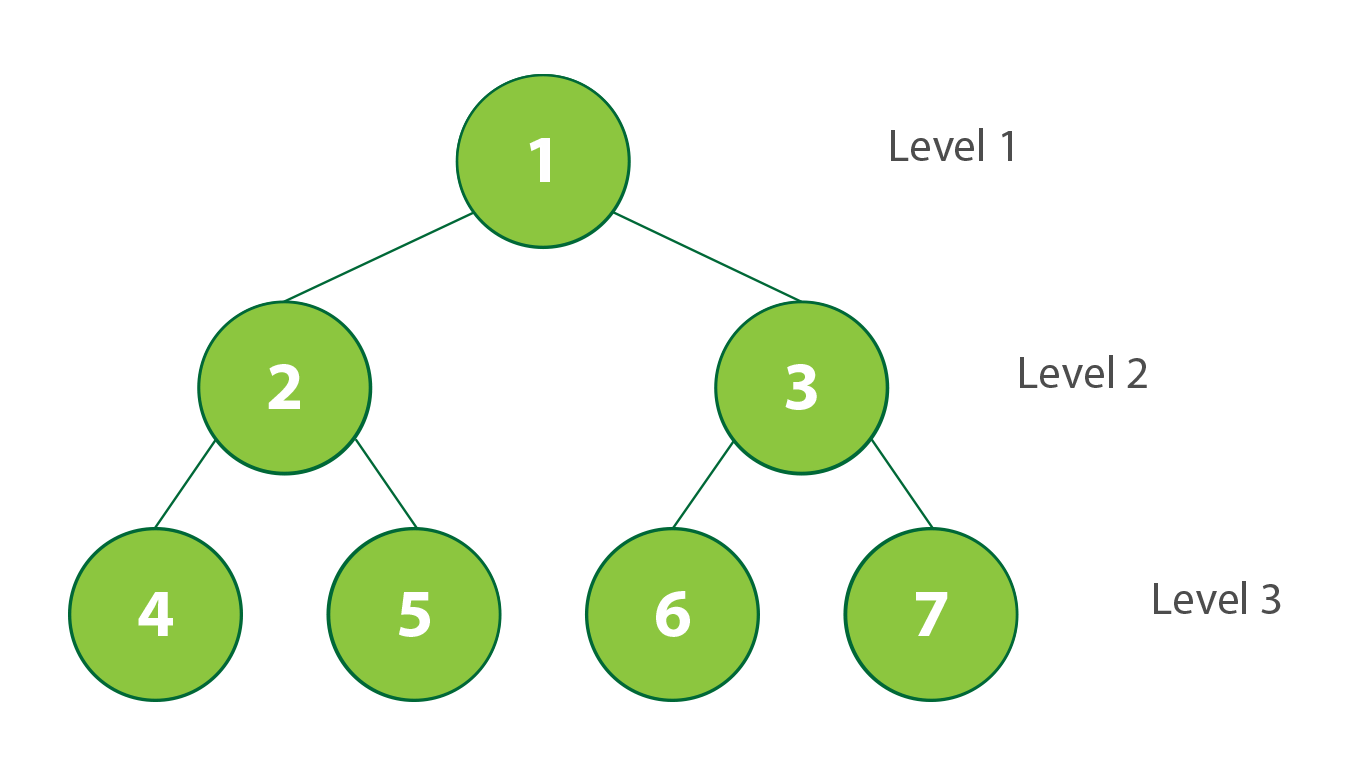 |
|---|
| Breadth-first Traversal in BST. Created by Stephanie Wong |
Clear the whole tree
void clear( BSTNode *&tree )
{
if ( !isEmpty( tree ))
{
clear( tree->left );
clear( tree->right );
delete tree;
tree = nullptr;
}
}
Removal of element
| Case | Action | Example |
|---|---|---|
| Case I: Node to be removed has no children | Simplest case. Algorithm sets corresponding link of the parent to NULL and deletes the node | remove( tree , -4 ) |
| Case II: Node to be removed has one child | It this case, node is cut from the tree and algorithm links single child (with it’s subtree) directly to the parent of the removed node | remove( tree , 18 ) 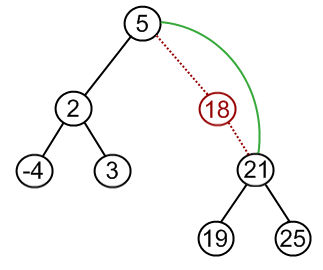 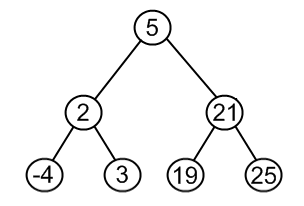 |
| Case III: Node to be removed has two children | This is the most complex case. To solve it, (1) find a minimum value in the right subtree; (2) replace value of the node to be removed with found minimum. Now, right subtree contains a duplicate! (3) apply remove to the right subtree to remove a duplicate. |
 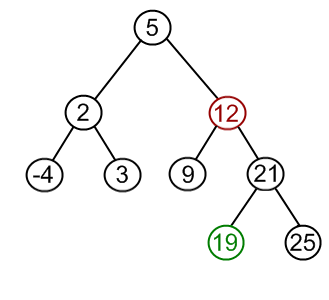 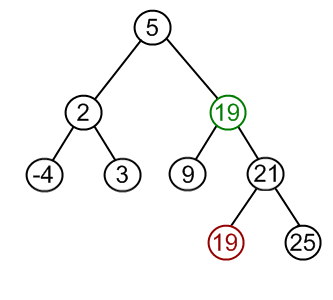  |
| Source: http://www.algolist.net/ |
void remove( BSTNode *&tree, int data )
{
if ( isEmpty( tree )) return;
if ( data == tree->data )
{
if ( !isEmpty( tree->left ) && !isEmpty( tree->right ))
{
BSTNode *minRight = minNode( tree->right );
tree->data = minRight->data;
remove( tree->right, minRight->data );
} else
{
BSTNode *discard = tree;
if ( isLeaf( tree ))
tree = nullptr;
else if ( !isEmpty( tree->left ))
tree = tree->left;
else
tree = tree->right;
delete discard;
}
} else if ( data < tree->data )
remove( tree->left, data );
else remove( tree->right, data );
}
Asbtract Data Types Built Upon BST
Set
We can harness the sorted property of BST to make efficient insertions and removals. Also, with a slight modification to the insert function, we can make this function only insert unique values, hence our new set (ADT) will always contain unique values.
Operations
isEmpty: same as BSTsize: same as BSTcontains: same asfindof BSTremove: same as BSTinsert: slight modification ofbst::insert, such that insertion is done when the element isn’t a duplicate of existing element, possible implementation:- use
containsto check if element doesn’t already exist, - then, if the condition holds, use
bst::insert, otherwise, do nothing.
- use
union: given two sets $S_1$ and $S_2$ make a new data structure $S_3 = S_1 \cup S_2$, possible implementation:- make an empty set
S3, - iterate over elements of
S1inserting each element toS3, and similarly forS2.
- make an empty set
intersect: given two sets $S_1$ and $S_2$ make a new data structure $S_3 = S_1 \cap S_2$, possible implementation:- make an empty set
S3, - iterate over elements of
S1inserting each element that also exists inS2intoS3.
- make an empty set
equals: given two sets $S_1$ and $S_2$, check the equality of the two sets, possible implementation:- first, check that $S_1$ and $S_2$ sizes are equal,
- then, iterating in-order in parallel in both $S_1$ and $S_2$ to validate the equality of traversed elements.
Map
Synonyms: Associative containers, dictionary, symbol table.
A map is a collection of searchable key-value pairs, where each key has a value.
Example 1, we can have a map representing count of words in a page or textbook, so the key here is the word, while the value is the count of this word.
Example 2, for the function that counts characters in DNA:
int countCharacter( std::string dna, char query )
{
int count = 0;
for ( int i = 0; i < dna.size(); ++i)
{
if ( query == dna[i] )
++count;
}
return count;
}
int main( int argc, char **argv )
{
if( argc == 2 )
{
std::string dna = getDNA( argv[1] );
int countA = countCharacter( dna , 'A');
int countC = countCharacter( dna , 'C');
int countG = countCharacter( dna , 'G');
int countT = countCharacter( dna , 'T');
std::cout << "A:" << countA << std::endl
<< "C:" << countC << std::endl
<< "G:" << countG << std::endl
<< "T:" << countT << std::endl;
}
return 0;
}
This function was called four times (i.e to count A, C, G, and T). However, by using map data structure we can run this function to count all characters in a single run!
int main( int argc, char **argv )
{
if( argc == 2 )
{
std::string dna = getDNA( argv[1] );
char_map::CharMap dnaCounter = char_map::create();
for( int i = 0 ; i < dna.size() ; ++i )
map::value( dnaCounter , dna[i] )++;
char_map::printAll( dnaCounter );
}
return 0;
}
Another important usage of map (ADT) is to implement a graph (ADT) by:
- representing each node in the graph as a key,
- and the associated value to that key is a list of the connected nodes.
Implementing a Dictionary (i.e Map) Using BST
Map implementation using BST would be as easy as implementing a set using the concrete routines of BST.
create: returns empty dictionary.isEmpty: checks if dictionary is empty.size: returns the size of the dictionary.insert: inserts new key to the dictionary.remove: remove an element by its key.at: returns a reference to the value associated with a given dictionary. Crashes if the key is not found.value: returns a reference to the value associated with a given key. If key not found, then insert a new key with the given key then returns a reference to the newly created value.contains: checks if a key exists in the dictionary.
struct MapNode
{
std::string key;
int value;
MapNode *left;
MapNode *right;
};
using WordMap = MapNode *;
Syntactical Sugar
One usage of C++ aliases, is abstraction of types. In the line using WordMap = MapNode *;, we are making an alias for a pointer type naming it WordMap. Now, we wish, in the main function, to pay no attention to the implementation details of our map. So, we wish not to see any asterisks (pointer) in the main function.
Since we decided to hide the implementation details in the main function, we hope not to initialize an empty map using the following syntax:
int main()
{
map::WordMap wmap = nullptr; // Correct. But, something vague here!
}
// In the above snippet, we should have a prior knowledge about the alias WordMap that represents a pointer, so we initialize it with nullptr.
A much better and clean solution is to write a function that returns an empty map. Hence, we hid our assumptions and conventions from the map user in the main function.
WordMap create()
{
return nullptr;
}
Now, in the main function it becomes cleaner to have an empty map using the following syntax:
int main()
{
map::WordMap wmap = map::create(); // Much cleaner!
}
bool isEmpty( WordMap wmap )
{
}
bool isLeaf( WordMap wmap )
{
}
int size( WordMap wmap )
{
}
bool find( WordMap wmap, std::string key )
{
}
int &at( WordMap wmap, std::string key )
{
}
void insert( WordMap &wmap, std::string key )
{
}
WordMap minNode( WordMap wmap )
{
}
void remove( WordMap &wmap, std::string key )
{
}
int &value( WordMap &wmap , std::string key )
{
}
void clear( WordMap &wmap )
{
}
void printAll( WordMap wmap )
{
}
Exercise and Assignment: Text Processing
Clone your group lab work and assignment from this link.
Consider the following text for Carl Sagan
Look again at that dot. That’s here. That’s home. That’s us. On it everyone you love, everyone you know, everyone you ever heard of, every human being who ever was, lived out their lives. The aggregate of our joy and suffering, thousands of confident religions, ideologies, and economic doctrines, every hunter and forager, every hero and coward, every creator and destroyer of civilization, every king and peasant, every young couple in love, every mother and father, hopeful child, inventor and explorer, every teacher of morals, every corrupt politician, every “superstar,” every “supreme leader,” every saint and sinner in the history of our species lived there on a mote of dust suspended in a sunbeam. The Earth is a very small stage in a vast cosmic arena. Think of the rivers of blood spilled by all those generals and emperors so that, in glory and triumph, they could become the momentary masters of a fraction of a dot. Think of the endless cruelties visited by the inhabitants of one corner of this pixel on the scarcely distinguishable inhabitants of some other corner, how frequent their misunderstandings, how eager they are to kill one another, how fervent their hatreds. Our posturings, our imagined self-importance, the delusion that we have some privileged position in the Universe, are challenged by this point of pale light. Our planet is a lonely speck in the great enveloping cosmic dark. In our obscurity, in all this vastness, there is no hint that help will come from elsewhere to save us from ourselves. The Earth is the only world known so far to harbor life. There is nowhere else, at least in the near future, to which our species could migrate. Visit, yes. Settle, not yet. Like it or not, for the moment the Earth is where we make our stand. It has been said that astronomy is a humbling and character-building experience. There is perhaps no better demonstration of the folly of human conceits than this distant image of our tiny world. To me, it underscores our responsibility to deal more kindly with one another, and to preserve and cherish the pale blue dot, the only home we’ve ever known.
Prelimenary Statistics
| Total count of words | count of words after removing duplicates (i.e word set) |
|---|---|
| 362 | 205 |
Comparing std::strings
Insertion and removal in BST depends in comparison in each step between the tree nodes. When we compare integers, we simply use the <, <=, >, >=, == operators. What if we need to compare strings lexicographically (i.e in order to be alphabetically ordered)?
Fortunately, std::string comes with a lot of embedded functions. We are going to use the embedded compare function.
#include <string>
int main()
{
std::string s1 = "batman";
std::string s2 = "superman";
int comparison = s1.compare( s2 );
}
| comparison value | explanation |
|---|---|
| positive | it means that s1 comes after s2 alphabetically, which is not the case |
| negative | it means that s1 precedes s2 alphabetically, which is the case |
| 0 | it means that s1 equals s2, which is not the case |
Lab work: Extract Set of Words in a Text using Set (ADT)
- Complete the source code in
set.hppto produce a set ofstd::strings. - Complete the source code in
unique_words.cppto print the set of words of the given file.
Group Assignment 1-A: Implement a Dictionary That Maps Characters to Integers
You are required here to develop a dictionary that has char as a key and int as a value. We will use this dictionary to keep track of each character count.
- Complete the implementation in
cmap.hpp, to produce a a dictionary that mapschartoint. - Complete the source code in
countDNA.cpp, to count each base in the given dna file using the developed dictionary.
Group Assignment 2-B: Evaluate the count of each word in a text using Map (ADT)
- Complete the implementation in the
map.hppfile to produce a dictionary that mapsstd::stringtoint. - Complete the source code in
count_words.cppto count each word in the given text file.